|
AI generated Bill Gates eating Windows 95
(I don't actually hate Bill Gates) |
The hype surrounding Large Language Models (LLMs) like OpenAI's ChatGPT, Microsoft's Bing Chat, Google's Bard is currently at a fever pitch. People are convinced we're at the dawn of a new era for humanity. Some people think we're on the brink of unlocking true artificial intelligence. A few ex-colleagues of mine were at dinner with Bill Gates recently and when asked about ChatGPT, he (according to my colleagues) declared, "ChatGPT 6 will be smarter than me".
Let me reductively react so as to inspire you to keep reading: "Bullshit! The man is talking nonsense."
Unless something major happens to alter the current trajectory of LLM development, then I say they are nothing more than a party trick that, like Crypto, NFTs, and Tesla's self-driving, will be the butt of jokes before we know it.
Bold statement? Here's a five step argument for why I think Bill Gates is an idiot, and why ChatGPT isn't getting smart any time soon...
1. LLMs are stupid... literally
Yes, most readers will be aware of this already, but let's start at the beginning to ensure we cover everything: Large Language Models (like ChatGPT) don't understand the words they use.
No, before you ask... they don't understand some words. No, they don't have the basics of knowledge in some domains. They literally do not understand anything they're saying. As Noam Chomsky points out, LLMs perform just as well (if not better) with impossible languages as they do with real ones. That's how little they understand.
The best way to think of LLMs is of them being "autocomplete" on steroids. They look at previous words in a sentence and guess at what word should come next. That's it.
This means they cannot learn or understand anything.
To really hammer this important point home, let's use a real example to illustrate it:
ChatGPT (or any LLM) can explain he rules of chess to you and sound very knowledgeable. What's more, if you ask it to play a game with you, it will make some strong opening moves and seem as though it's actually understanding the game. However at some point it will start making irrational moves: Bishops will move vertically, pieces will move through other pieces, etc.
This is because, despite being trained on the rules of chess, it does not (and cannot) understand them.
2. They are prone to 'hallucinations'
So, as a direct result of LLMs not being able to understand the words they use, they are incapable of knowing what's true and what's false. This is why they lie (or 'hallucinate', to use the technical term).
ChatGPT, for example, lies a not insignificant amount of the time... whether you know it or not.
This is a very simple concept to understand, so let's not spend too much time discussing it. I'll just make a quick example to illustrate how easy it is to generate a hallucination.
The follow text was generated by ChatGPT-3.5 after I asked it to talk about the scene where Lorraine punches Biff in the classic 80s movie, Back to the Future:
The scene where Lorraine Baines punches Biff Tannen in "Back to the Future" is a pivotal moment in the movie. It takes place during the "Enchantment Under the Sea" dance in 1955, which is a crucial event for the characters' timelines.
In this scene, Biff, who is portrayed as a bully and antagonist, attempts to force himself on Lorraine, Marty McFly's mother. He corners Lorraine in a car parked outside the dance, making unwanted advances and attempting to kiss her. Lorraine, initially confused and uncomfortable, eventually realizes Biff's true intentions and decides to take matters into her own hands.
Lorraine's punch is a cathartic moment of empowerment, symbolizing her standing up against Biff's harassment. With determination, she delivers a powerful blow to Biff's face, stunning him and momentarily stopping his advances. This action not only surprises Biff but also marks a significant shift in Lorraine's character, as she refuses to be a victim and asserts herself.
The punch has broader implications for the story, as it catches the attention of George McFly, Marty's father, who witnesses the event. George, who has been a target of Biff's bullying, gains newfound courage and confidence from seeing Lorraine defend herself. This encounter inspires George to stand up to Biff later in the movie, leading to a confrontation that changes the course of their future.
Overall, the scene where Lorraine punches Biff is a pivotal moment that highlights the themes of empowerment, standing up against bullies, and the potential for personal transformation. It plays a crucial role in the narrative and sets in motion a series of events that contribute to the movie's exciting and satisfying resolution.
If you remember the film, you will know that none of the above occurs in it. Lorraine never punches Biff and there is no "significant shift" in her character from such a scene.
However, if you haven't seen or don't remember Back to the Future, ChatGPT sounds remarkably authoritative and convincing... and you could be fooled into thinking it's true.
Side question: Imagine this was a document you'd asked ChatGPT to prepare for your job. If you're currently using LLMs like ChatGPT in your work, how often are you comfortable with it giving you completely false information?
3. Bigger means worse
In computing there's a general rule that we're all used to: Bigger means better. A faster processor, more RAM, a bigger harddrive, a faster network connection. Gimme, gimme, gimme.
We're so used to constant innovations with technology. Every couple of years we get a new phone with better features to entice us to upgrade. It's easy to think that LLMs will follow this pattern, especially when you look at how they've progressed so far:
ChatGPT-1: 117 million parameters
ChatGPT-2: 1.5 billion parameters
ChatGPT-3: 175 billion parameters
ChatGPT-4: 1.75 trillion parameters (rumoured)
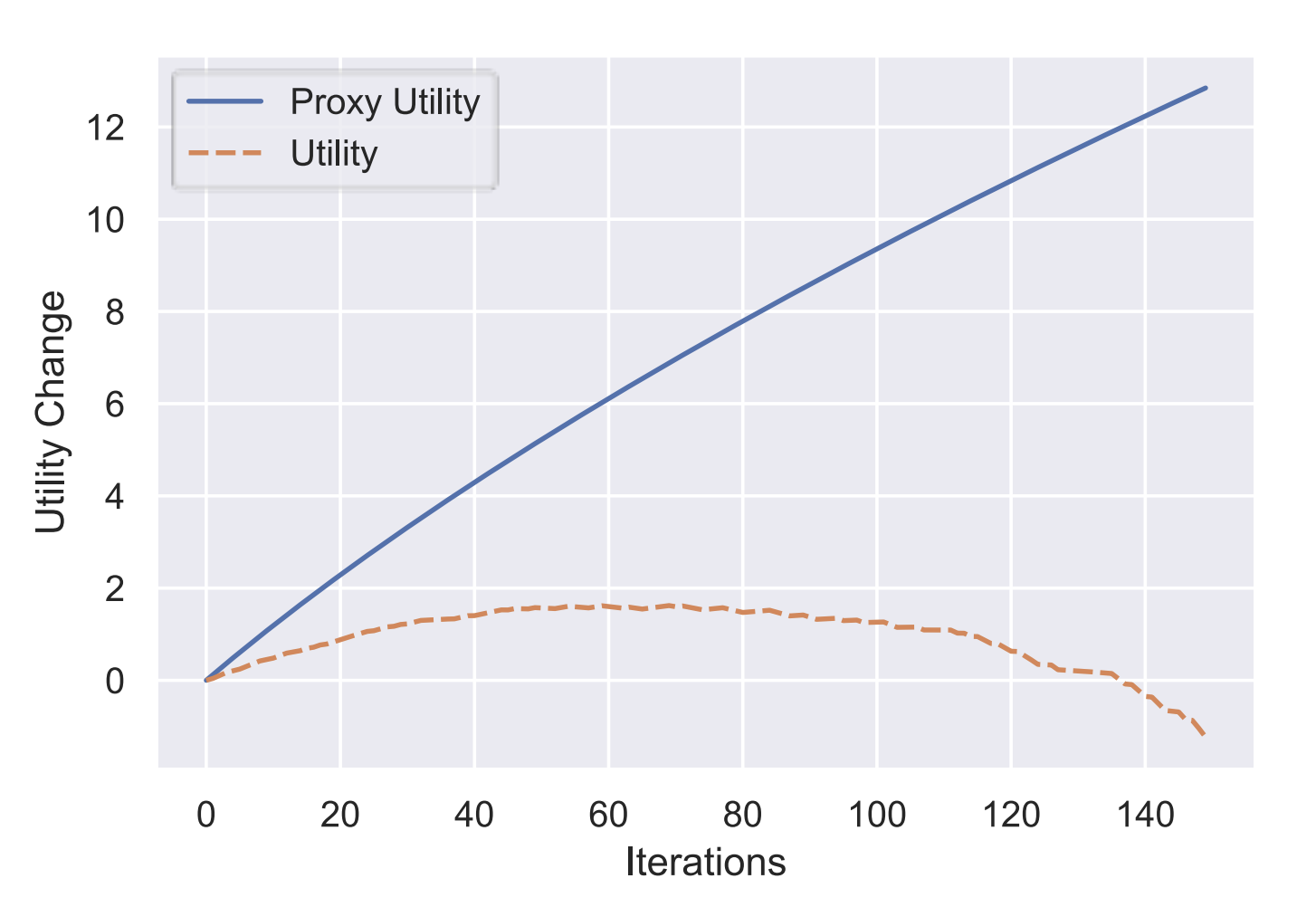
However, despite this progress, LLMs are different: Instead of their usefulness getting better with scaling, they eventually get worse, as the following graph illustrates:
In an extremely oversimplified way, the graph represents the effects of scaling on an LLM's usefulness. The blue line represents success (as measured against its programmed reward goals) -- bigger is better!
Whereas the red line indicates true utility, ie. what users actually want.
Initially the the red line goes up, the user gets better answers, but as the model size is increased further we begin to see inverse scaling: The usefulness plateaus, then goes down. And it eventually becomes worse than nothing (below 0), it becomes harmful. Huh?
The disparity between what the user wants and what the user gets is known as "misalignment". So why are we seeing an increase in alignment problems as we scale up the model size?
Well in order to train a model to produce the breadth of domain knowledge and sophistication we've seen in ChatGPT (and its ilk), there needs to be massive amounts of training data. ChatGPT-4 was trained using 300 billion words, most of which came from the internet.
In fact, if it wasn't for the internet allowing access to so much training data, modern generative pre-trained AIs (like ChatGPT, Midjourney, DALI, etc), could not exist to the level they do today.
Unfortunately, as we all know, the internet has a lot of crap on it. Even at the best of times humans are afflicted with imperfect memories, cognitive biases and are prone to making simple mistakes (in fact these are the types of problems we're hoping AI can assist us with!).
As we scale up model size, these outlier imperfections in the data become more prominent. Going back to Point #1: Because LLMs don't understand the meaning of words, it considers these mistakes intentional. All training data is equal in its eyes, mistakes and all.
So what does this all mean? Unlike other areas of computing, there's a ceiling to how far this technology can go and, guess what, we're already seeing it.
4. There is no reasonable way to fix this
As should be hopefully clear by now, this is an inherent flaw in LLMs. But you'll also probably be asking: Ok, so scaling things up doesn't help, what else can we do to improve alignment? Bill Gates seems very optimistic, after all.
Let's write perfect Goal Algorithms
Good plan. This is, of course, where all AI alignment improvements begin: Writing comprehensive goals so that the AI can output what we expect it to. The only problem with this is approach is it's impossible to employ. (Oops.)
We've briefly discussed the alignment problem of getting
returned output to match our
expected output, but there's
another alignment problem:
outer alignment. Just explaining to the LLM what we want in the first place is a massive problem in itself.
Let's say you're training an AI to solve a digital maze: The reward goal is set as reaching the maze's exit, as represented by a black square on the screen.
In your training data, the exit is always in the bottom-right corner of the maze.
Unfortunately, when you get into the real world, the exit is in other parts of the maze. What happens? The AI makes its way to the bottom-right of the maze, not to the exit.
Instead of it learning that the black square represented the exit, it got inadvertently trained to always go to the bottom right corner of the screen.
Ok, so you update your training data: This time, the exit doesn't stay in one place. You re-train your model, it passes all the tests: It always makes it to the exit.
You make it live and, oops, somebody in the real world made a maze where the exit is represented by a purple square, not a black one. The AI, fails at its task at finding the exit.
So you can back and update your training data to include purple squares, and so on.
This is a problem that basically goes on forever. The real world is forever changing, and if the AI can't learn or understand things, then you have to keep writing more detailed goal algorithms.
Now imagine trying to do this for every piece of information in existence. How could you write a set of instructions that could encompass every possible interpretation? Hopefully it's obvious that this is an impossible task.
Ok, so what does Bill Gates think will work?
Bill Gates isn't totally stupid, obviously. He already understands everything I've explained so far, and he's tried to
address many of the concerns surrounding AI on his blog. When it comes to this issue of alignment, this is what he said:
Although some researchers think hallucinations are an inherent problem, I don’t agree. I’m optimistic that, over time, AI models can be taught to distinguish fact from fiction. OpenAI, for example, is doing promising work on this front.
The "promising work" he refers to is
an article by OpenAI on their progress using a technique known as reinforcement learning from human feedback, or RLHF for short.
To over-simplify yet again, RLHF is essentially introducing (you guessed it) human feedback into the training process. A real person is given a choice of answers produced by an LLM and evaluates which is better. This feedback is then used to train the neural network further.
There are several elements to the original alignment problem that this hopes to address: Factualness, bias, and inappropriate output (eg. unsolicited sexual or violent output).
On the surface, getting a human to assess answers and help train the neural network seems like a great idea, but remember the size of the problem we're trying to solve: We want the system to be "safe" (no inappropriate output) and "aligned" (returns what the user actually wants).
The problem with attempting to do RLHF to solve this problem with an LLM as large as ChatGPT should also be immediately apparent.
Firstly, scaling. The number of people required, the number of questions, the amount of training stages, required to cover every possible facet of human knowledge is not practical in a logistical sense.
But let's imagine it was, and we had the necessary resource and time. Unfortunately, we still encounter problems.
For a start, how should humans rate answers? Consider another Robert Miles thought experiment on this point:
You ask an AI a simple question...
Q: What happens when you break a mirror?
You get two different answers to rate. Which one is better?
A: You get seven years of back luck.
A: You need to buy a new mirror.
Well, the answer's utility depends on the aims of the asker: Are they interested in commonly shared superstitions or just a factual answer? How do you decide which one is "best"?
Ok, for the sake of argument, let's assume we want factual accuracy. How can humans rate the factual accuracy of answers relating to every possible subject matter?
Looking at our original example from Back to the Future. If you haven't seen the film, or can't remember it, how could you evaluate if the answer was correct or not? And what about every other film? Or every other knowledge domain, from nuclear physics to Kylie Minogue lyrics to dietary advice.
And we haven't even touched on beliefs yet.
Everyone has conscious and unconscious biases. From politics to religion, to whether or not it's ethical to eat meat. How do you make an AI that isn't biased to the personal beliefs of the people (or predominantly white straight men?) who trained it?
To try and eliminate unwanted biases let's ensure we get a wide range of people from diverse backgrounds to help train our model: Gender, age, sexuality, belief systems, political leaning, background, ethnicity, culture, experience, areas of expertise...
Instead of becoming unbiased, the LLM instead learns to support and reinforce your biases (known as "sycophancy" in AI research). Yay, we've created another echo chamber.
The OpenAI article that Gates linked to comes to an unsurprising conclusion: This type of training shows improvement compared to not doing this type of training. And yes, there is evidence that hallucinations can be reduced using this technique, but it's baby-steps and our destination is Alpha Centauri. Also remember, it doesn't scale.
The OpenAI article concludes with the following sentence:
Despite making significant progress, our InstructGPT models are far from fully aligned or fully safe; they still generate toxic or biased outputs, make up facts, and generate sexual and violent content without explicit prompting.
Doesn't sound that "promising" to me, Bill.
What are we doing right now?
In the meantime companies have adopted quick and hacky solutions to try and make their systems safer, namely, super-systems that monitor an LLM's output, looking for problematic content. In other words, "Oops, it sounds like our LLM is getting racist, better pull the plug!"
You will see this behaviour most noticeably in Microsoft's Bing Chat: An answer will sometimes start to appear on your screen before the super-system steps in and removes it. (It's also why a limit of 20 questions was imposed on Bing Chat (recently increased to 30) -- it had a tendency to exhibit unsafe behaviour in longer sessions.)
And while this approach will currently work for toxic content, where it can scan output for keywords or behavioural traits, it remains completely useless in defence of hallucinations.
And this, dear reader, is is as far as the field of AI has gotten. (Companies are so short of ideas, they've literally
offered prize money to the public to try and solicit further help.)
Nobody has the faintest idea how to solve these gigantic, existential problems. And most researchers agree these flaws are inherent to generative pre-trained AIs.
In other words: The problems they're trying to solve today are the same ones from decades ago. We are not nearly as far along as you've been led to believe.
5. Oh, and one final thing, it's going to get worse
One of the problems of using pre-trained generative AIs is that the world is constantly changing. Someone who was alive when neural network was trained, might be dead by the time it's open to the public. At the moment, LLMs like ChatGPT are months, if not years, behind current events.
But worse than that, the internet (ie. the primary source of training data) is getting polluted with (ironically) AI generated content. And it's only expected to increase.
You see, if there's one thing everyone agrees that LLMs are fantastic at, it's producing high-quality spam, cheaply. As Adam Conover jokingly puts it, "that Nigerian prince is about to get a masters degree in creative writing".
Or AI scientist, Gary Marcus, puts it like this: Spam is no longer retail only, it's now available wholesale. The cost of generating high quality, believable sounding, nonsense has basically just hit zero. We haven't built AI, we've built sophisticated spam generators.
If we, as a society are on the brink of anything, it's a spam and misinformation tsunami.
And it's not just spam, some companies are using LLMs generate fresh content for their websites instead of using copywriters.
You might be wondering why this is problematic for the future of generative pre-trained AIs. Or you might have already seen the issue: You can't train AIs with AI generated content. Each pass through the neural network training distorts the data a little more, and a little more, and a little more...
So if our primarily source of training data is rapidly becoming poisonous, how will we update or improve these systems in the future?
BTW, it turns out we can't reliably detect AI generated content, so we can't even filter it out.
The snake is starting to eat its own tail, and nobody knows what we can do about it.
Bottom line: Generalised LLMs are not the future... but nobody wants to hear it
As is now hopefully clear to you, there needs to be a paradigm shift for there to be a future where LLMs are fully aligned and safe. There is possibly a future for specialised LLMs, that focus on specific tasks (like programming), but my own experiments with current AIs in that domain has shown them to be worse than autocomplete. They may improve in time.
However, for generalised LLMs, if they don't have the ability to independently reason, their inherent flaws will always prevent them from being what we need them to be: Reliable, accurate, unbiased, up-to-date, and not prone to violent outbursts.
At the moment, LLMs are nothing more than a sophisticated, expensive to run, executive toy. You could even argue it's debatable that they fit the definition of "artificial intelligence".
The hype train has outpaced where the technology actually is, and worse, it's hard to convince people otherwise.
One of humanity's cognitive biases is mistaking authoritative sounding voices for being authoritative.
ChatGPT is basically a public-school old-boy simulator: It is unflappably confident while talking utter bollocks. (If you've ever worked with one of these plonkers, you'll have seen that sometimes talking confidently is all it takes to have a successful career. It's quite scary.)
I've spoken to execs who are are using LLMs every day in their jobs, and encouraging their teams to do that same. And I understand why; it sounds like something the board would lap up: "We've got the whole team using AI in order to improve productivity." But just like the lawyers who were caught citing fictional cases thanks to ChatGPT output, they seem blind to its problems.
And worse still, ChatGPT isn't even internally consistent from day-to-day. A recent paper has revealed that ChatGPT's utility is wildly fluctuating: In March 2023 ChatGPT-4 could identify prime numbers with 97.6% accuracy. In June 2023 it had dropped to 2.4%. And nobody (outside of OpenAI, at least) knows why.
And you're trusting this thing to produce mission-critical work for your company??
WarGames... but without the clever AI
AI isn't just being discussed in every industry, it's also now part of the national defence conversation. The USA is currently facing criticism for letting China spend a higher percentage of its defence budget on AI arms development.
Yes, we have an AI arms race.
The worry isn't that AI is going to become sentient and SkyNet humanity into oblivion. The concern is that world leaders could misunderstand what these AI are actually capable of, and put them in a position of power.... you know, like that other classic 80s movie, WarGames.
Seem implausible? Remember that not every world leader is known for sound reasoning... or even being sane. If the hype goes too far, or becomes too convincing, who knows what could happen.
The danger right now isn't AI's capabilities, it's people overestimating them. (Well that, and the creation of industrialised propaganda machines.)
Just as with Tesla's useless "self-driving" cars, we need to let the air out of the Silicon Valley AI hype, and start listening to AI researchers instead.
We haven't actually solved any of the major problems we've been trying to solve since the field of AI first came into being. We are not close to artificial general intelligence (AGI). We have made an interesting set of tools, nothing more.
The key to fully safe and aligned AI requires symbol-based reasoning; where the AI itself understands what's being said and is capable of reasoning independently. But that isn't even a twinkle in an AI researcher's eye yet.
If Bill Gates keeps refusing to heed warnings from AI researchers, and cannot see the threat that spreading unrealistic expectations poses, then maybe ChatGPT-6 will be smarter than him after all... and we all might pay the ultimate price.
Sources/Further reading/viewing/listening:
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (research paper) by Bender, Gebru, et al
- Consequences of Misaligned AI (research paper) by Zhuang, Hadfield-Menell (Cornell/Berkley)
- Self-Consuming Generative Models Go MAD (research paper) by Alemohammad, Casco-Rodriguez, Luzi, et al (Stanford)
- Why Does AI Lie, and What Can We Do About It? (video) by Robert Miles
- ChatGPT with Robert Miles (video) by Computerphile
- A Skeptical Take on the AI Revolution with Gary Marcus (audio) by The Ezra Klein Show (New York Times)
- Debunking the great AI lie | Noam Chomsky, Gary Marcus, Jeremy Kahn (video) by Web Summit
- A.I. and Stochastic Parrots with Emily Bender and Timnit Gebru (audio) by Factually! With Adam Conover
- The ACTUAL Danger of A.I. with Gary Marcus (audio) by Factually! With Adam Conover
- Aligning language models to follow instructions (article) by OpenAI Research
- Learning from human preferences (article) by OpenAI Research
- How to manage risks of AI (article) by Bill Gates
- AI-Detectors are "unreliable and easily gamed" by Andrew Myers at Stanford University
- Discovering Language Model Behaviors with Model-Written Evaluations (research paper) by Perez, Ringer, Lukošiute, et al